Java 序列化的主要目的有两个,网络传输和对象持久化。
Java序列化从JDK1.1版本就已经提供,它不需要添加额外的类库,只需实现java.io.Serializable并生产系列ID即可,因此,它从诞生之初就得到广泛的应用。
但是在远程服务调用(RPC)时,很少直接使用Java序列化进行消息的编解码和传输,这又是什么原因呢?下面通过分析Java序列化的缺点找出答案。
无法跨语言
无法跨语言,是Java序列化最致命的问题。对于跨进程的服务调用,服务提供者可能会使用C十+或者其他语言开发,当我们需要和异构语言进程交互时Java序列化就难以胜任。
由于Java序列化技术是Java语言内部的私有协议,其他语言并不支持,对于用户来说它完全是黑盒。对于Java序列化后的字节数组,别的语言无法进行反序列化,这就严重阻碍了它的应用。
事实上,目前几乎所有流行的JavaRCP通信框架,都没有使用Java序列化作为编解码框架,原肉就在于它无法跨语言,而这些RPC框架往往需要支持跨语言调用。
序列化后的码流太大
下面我们通过一个实例看下Java序列化后的字节数组大小。
代码清单1 Java序列化代码 POJO对象类UserInfo
Userlnfo对象是个普通的POJO对象,它实现了java.io.SerializabIe接口,并且生成了一个默认的序列号serialVersionUID=lL,这说明UserInfo对象可以通过JDK默认的序列化机制进行序列化和反序列化。
下面写一个测试程序,先调用两种编码接口对POJO对象编码,然后分别打印两者编码后的码流大小进行对比。
代码清单2 Java序列化代码 编码测试类 TestUserInfo
测试结果如图1所示。

图1 测试结果
测试结果令人震惊,采用JDK 序列化机制编码后的二迸制数组大小竟然是二进制编码的5.29倍。
我们评判一个编解码框架的优劣时,往往会考虑以下几个因素。
- 是否支持跨语言,支持的语言种类是否丰富;
- 编码后的码流大小:
- 编解码的性能;
- 类库是否小巧,API使用是否方便:
- 使用者需要手工开发的工作量和难度。
在同等情况下,编码后的字节数组越大,存储的时候就越占空间,存储的硬件成本就
越高,并且在网络传输时更占带宽,导致系统的吞吐量降低。Java序列化后的码流偏大也一直被业界所垢病,导致它的应用范围受到了很大限制。
序列化性能太低
下面我们从序列化的性能角度看下JDK的表现如何。
创建一个性能测试版本 的 PerformTestUserInfo测试程序 ,代码如下 。
代码清单3 Java序列化代码 编码性能测试类 PerformTestUserInfo
对Java序列化和二迸制编码分别进行性能测试,编码100万次,然后统计耗费的总时间,测试结果如图2所示。

图2 UserInfo编码性能测试结果
这个结果也非常令人惊讶:Java序列化的性能只有二进制编码的6.17%左右,可见Java原生序列化的性能实在太差。
下面我们结合编码速度,综合对比一下Java序列化和二进制编码的性能差异,如图3所示。
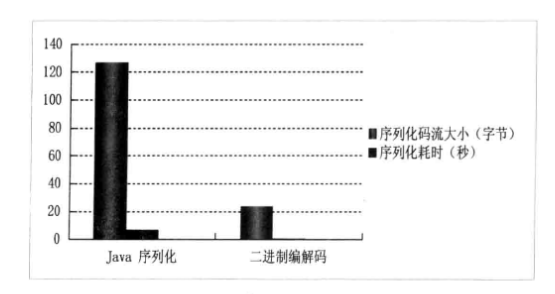
图3 序列化性能对比图
从图3可以看出,无论是序列化后的码流大小,还是序列化的性能,JDK默认的序列化机制表现得都很差。因此,我们边常不会选择Java序列化作为远程跨节点调用的编解码框架。
但是不使用JDK提供的默认序列化框架,自己开发编解码框架又是个非常复杂的工作,怎么办呢?不用着急,业界有很多优秀的编解码框架,它们在克服了JDK默认序列化框架缺点的基础上,还增加了很多亮点,下面让我们继续了解并学习业界流行的几款编解码框架,如MessagePack编解码、GoogleProtobuf编解码和JBossMarshalling编解码。

